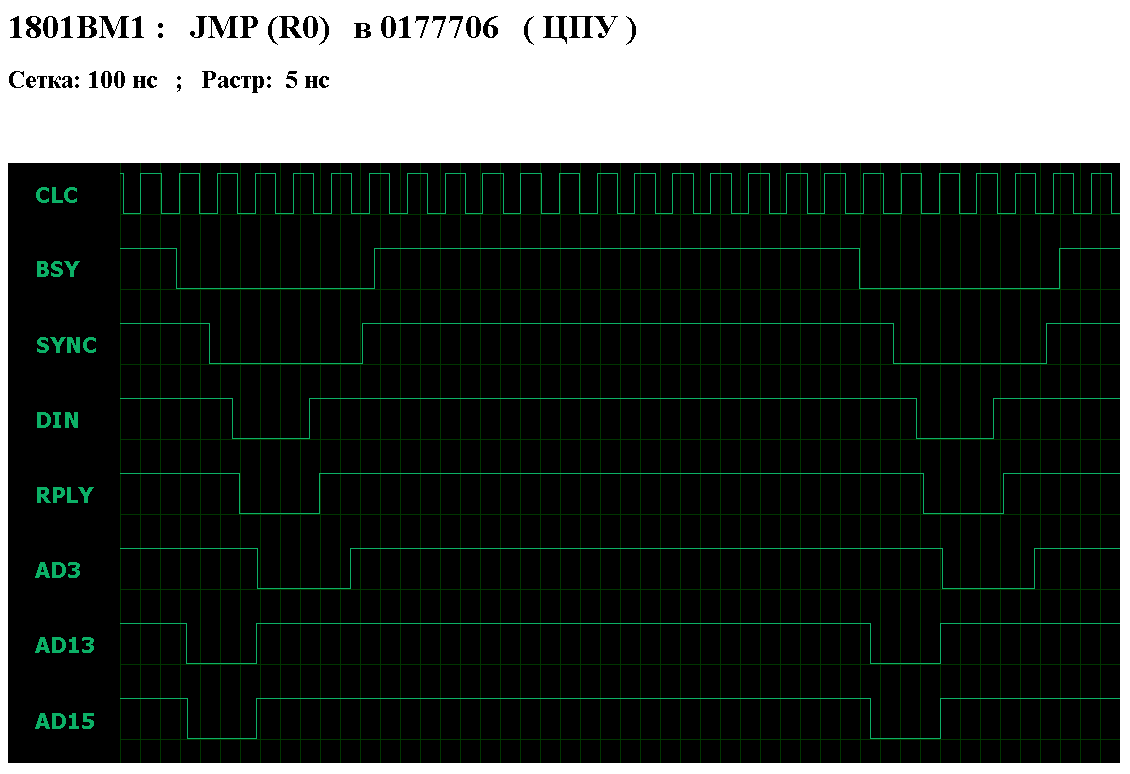
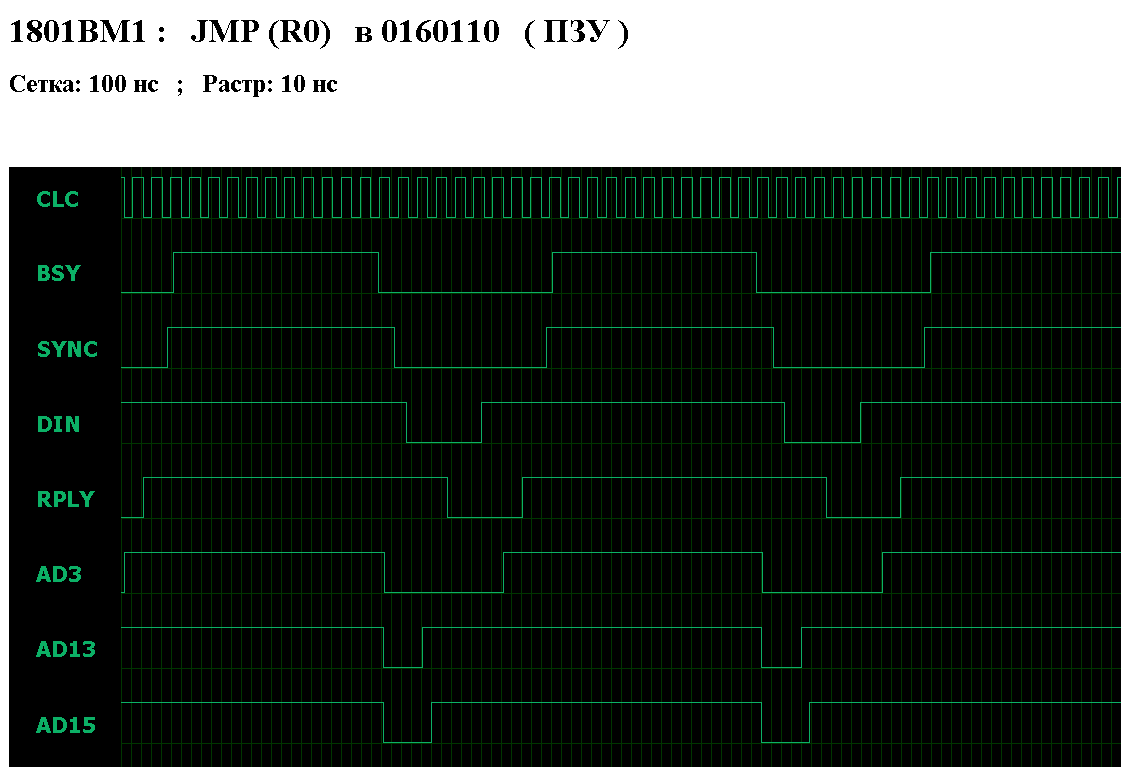
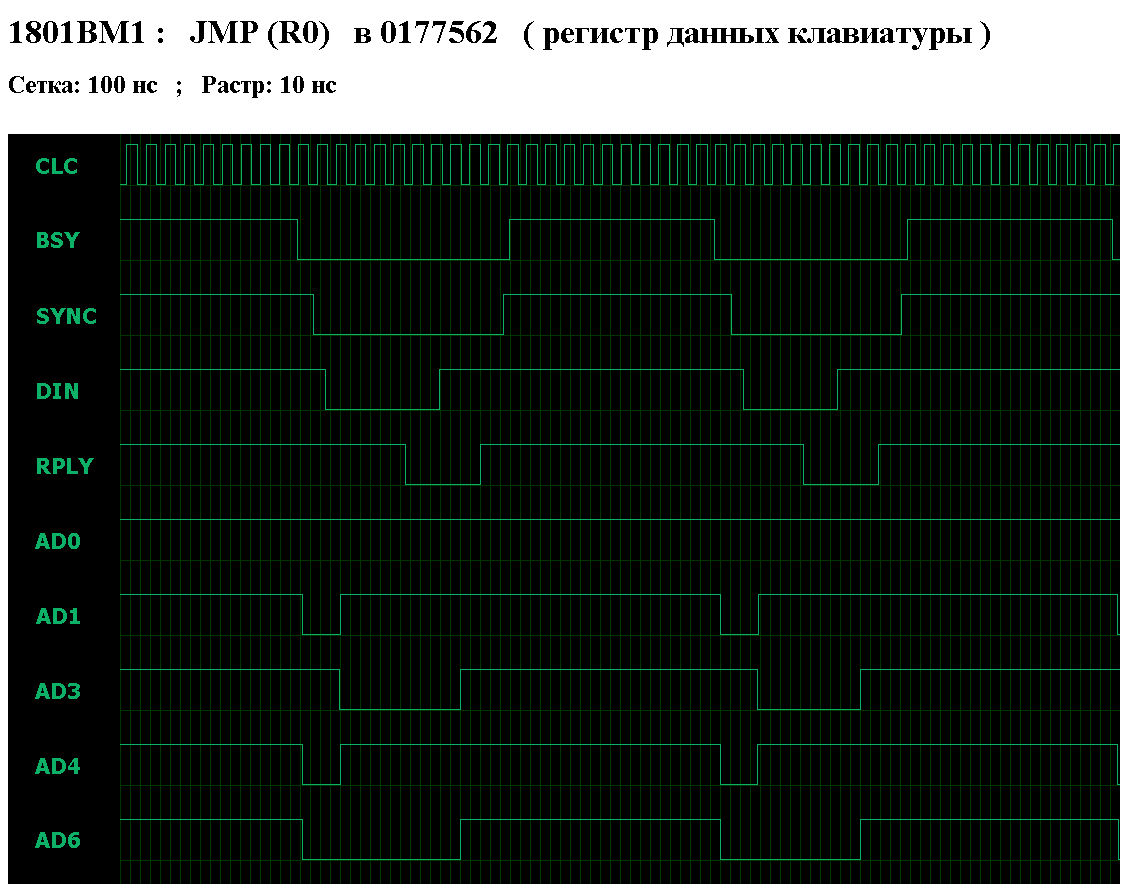
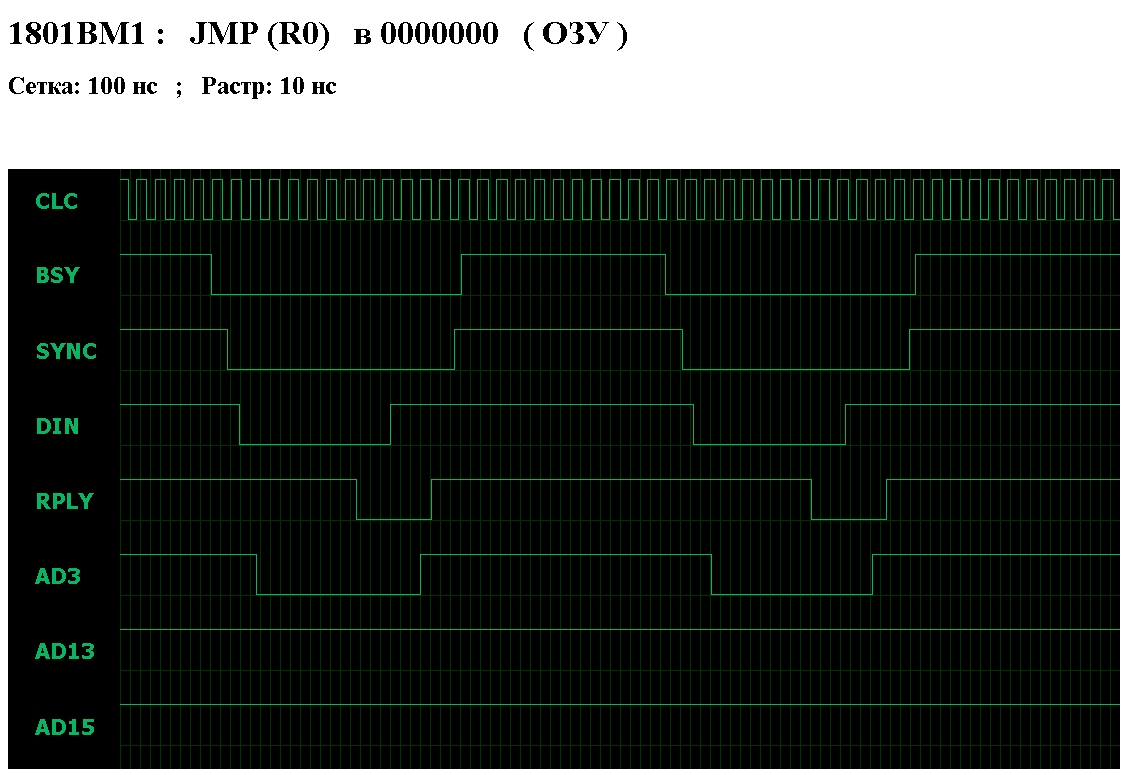
Исходные величины, одинаково влияющие на время выполнения процессором любой команды - это задержка шины и задержка ячейки ( образующие в сумме задержку доступа
Tadr ) и продолжительность такта процессора
T.
Задержка доступа различается по:
1. Типу адресуемой ячейки:
1.1 ячейка ОЗУ -
Tadr = Tram;
1.2 регистр устройства -
Tadr = Tdev;
1.3 ячейка ПЗУ -
Tadr = Trom
2. Типу доступа:
2.1 чтение
TadrR;
2.2 запись
TadrW;
2.3 модификация
TadrM.
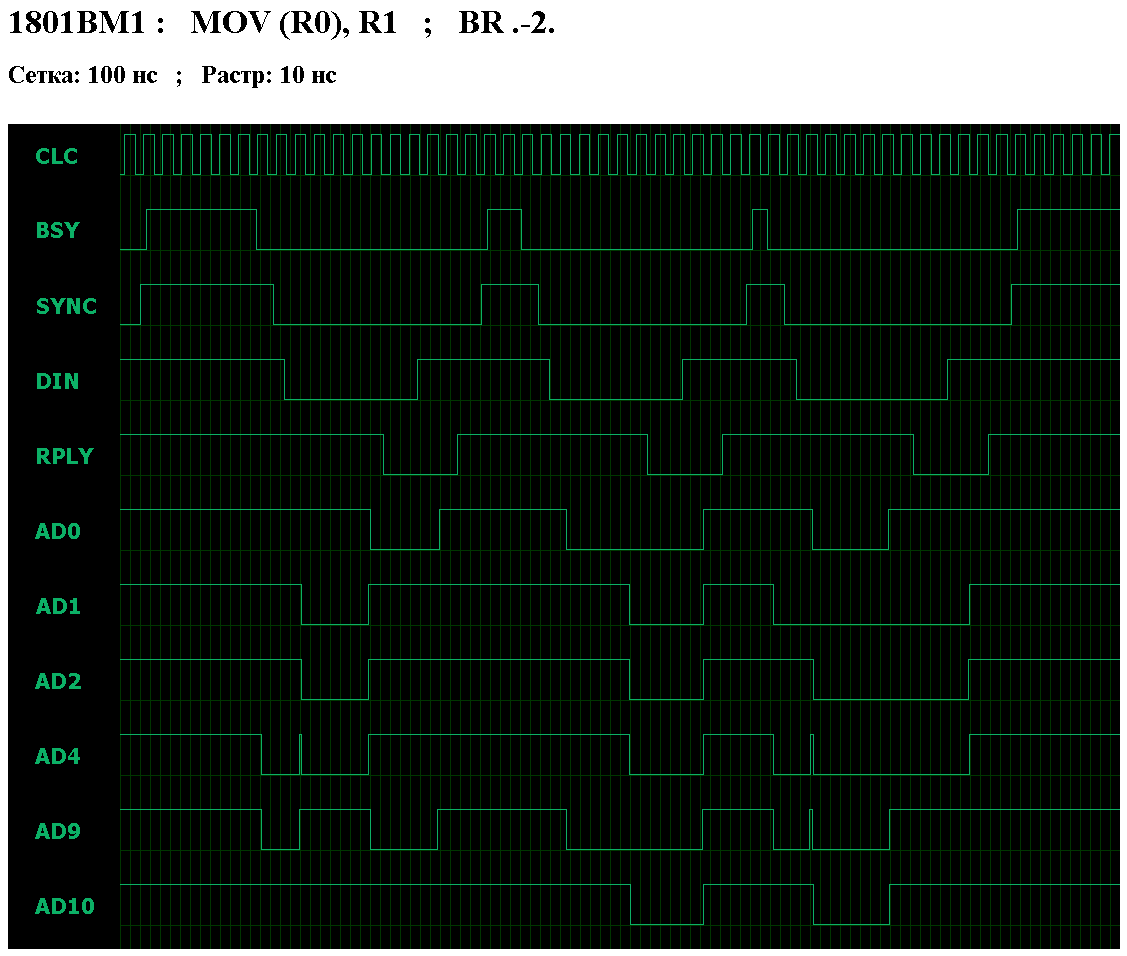
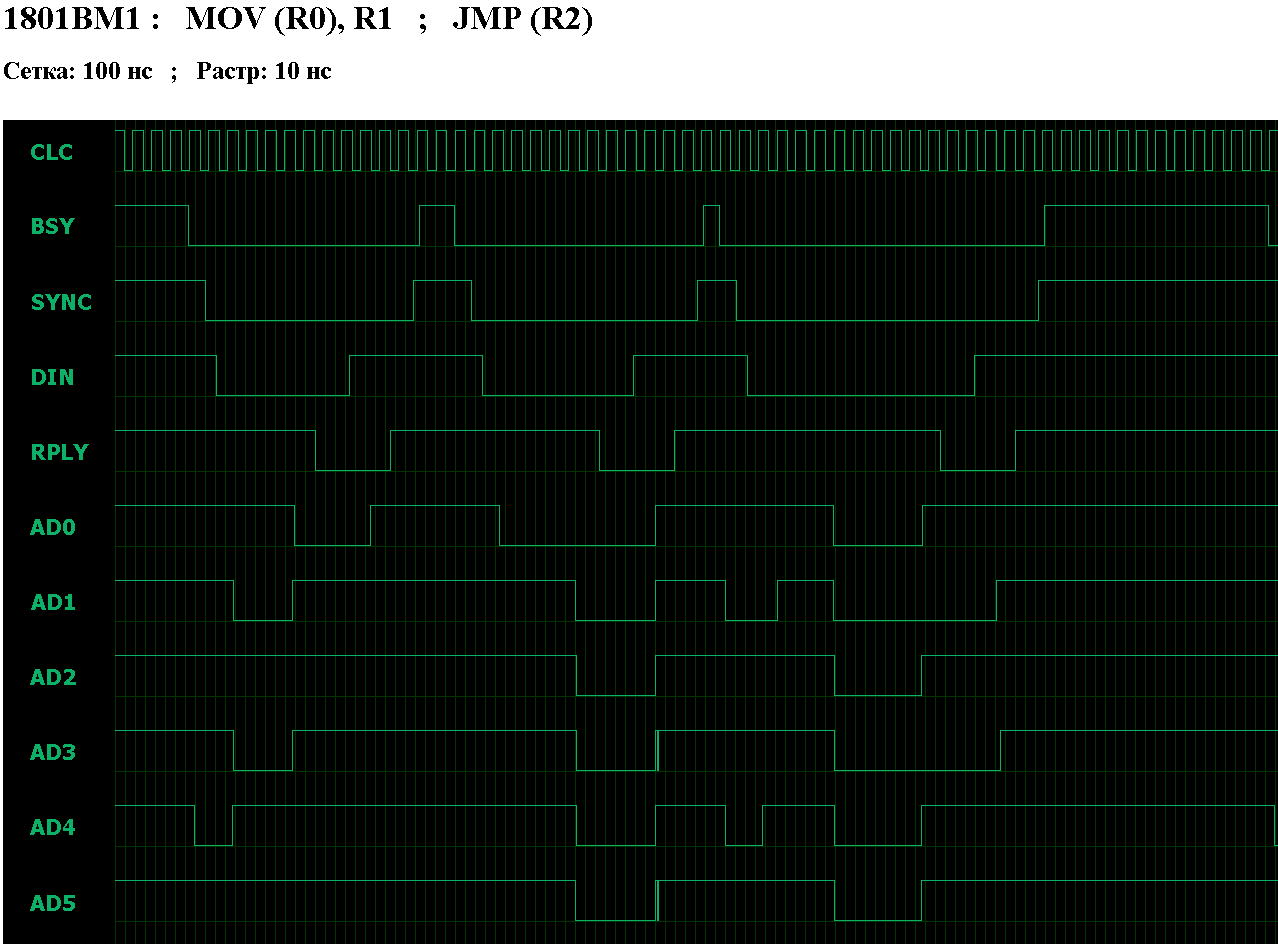
В данное время мне наиболее интересны параметры времени выполнения команд процессором 1801ВМ1.
Выборка команд из памяти у процессора 1801ВМ1 не конвееризована, поэтому время выполнения команды
NOP складывается из времени выборки команды ( TadrR ) и времени обработки команды ( 8*T ).
Значит, формула времени выполнения команды
NOP: Tnop = TadrR + 8T. Если команда NOP находится в ОЗУ, то это TramR + 8T, а если в ПЗУ - то TromR + 8T.
В справочниках есть упрощённые формулы вычисления времени выполнения команд 1801ВМ1:
Код:
Времена выполнения команд:
одноадресных двухадресных
метод время метод адресации время
адресации выполнения источн. приемн. выполнения
0 8T+tn 0 0 8T+tn
1 21T+3tn 1 0 18T+2tn
2 20T+3tn 2 0 18T+2tn
3 27T+4tn <Испр. 3 0 25T+3tn
4 21T+3tn 4 0 20T+2tn
5 28T+4tn 5 0 26T+3tn
6 27T+4tn 6 0 25T+3tn
7 34T+5tn 7 0 32T+4tn <Испр.
0 1 26T+2tn
Время выполнения команд 0 2 28T+2tn
управления HALT=54T+7tn 0 3 31T+3tn
команд IOT,BPT,EMT,TRAP 0 4 28T+2tn
42T+5tn; команд устано- 0 5 32T+3tn
вки и очистки признаков 0 6 31T+3tn
8T+tn; максимальное 0 7 40T+4tn
время ожидания ПДП 8T+ 1 1 28T+3tn
+2tn для цикла ввод-па- 2 2 30T+3tn
уза-вывод; максимальное 3 3 40T+5tn
время от момента запро- 4 4 31T+3tn
са прерывания до выбор- 5 5 42T+5tn
ки первой команды ново- 6 6 40T+5tn
го процесса 98T+12tn 7 7 56T+7tn
(время выполнения самой
длинной команды + IOT)
В таблицах приведены времена исполнения для одноадресных команд
COM, INC, DEC, ADC, SBC, ASR, ASL, ROL, ROR, CLR, и для двухадресных
ADD, SUB, BIC, BIS, XOR. За T обозначен период тактовой частоты процессора,
tn-время между выдачей DIN/DOUT и приходом RPLY.
Однако, здесь уже не всё так просто и очевидно, как в случае с NOP.
Начнём с одноадресных команд. Рассмотрим формулы времени выполнения команды INC в зависимости от используемого метода адресации:
Код:
0: INC R0 TadrR + 8T
1: INC (R0) TadrR + 8T + TadrR + 13T + TadrW
2. INC (R0)+ TadrR + 8T + TadrR + 12T + TadrW
3: INC @(R0)+ TadrR + 8T + TadrR + 19T + TadrW
4: INC -(R0) TadrR + 8T + TadrR + 13T + TadrW
5: INC @-(R0) TadrR + 8T + TadrR + 13T + TadrR + 7T + TadrW
6: INC 2(R0) TadrR + 8T + TadrR + 12T + TadrR + 7T + TadrW
7: INC @2(R0) TadrR + 8T + TadrR + 12T + TadrR + 7T + TadrR + 7T + TadrW
Как такое может быть, чтобы команда INC @-(R0) требовала ( для своего выполнения ) четырёх обращений к памяти, а команда INC @(R0)+ только ТРЁХ ???
Очевидно, что в справочнике ошибка - исправляем.
Код:
0: INC R0 TadrR + 8T
1: INC (R0) TadrR + 8T + TadrR + 13T + TadrW
2. INC (R0)+ TadrR + 8T + TadrR + 12T + TadrW
3: INC @(R0)+ TadrR + 8T + TadrR + 12T + TadrR + 7T + TadrW
4: INC -(R0) TadrR + 8T + TadrR + 13T + TadrW
5: INC @-(R0) TadrR + 8T + TadrR + 13T + TadrR + 7T + TadrW
6: INC 2(R0) TadrR + 8T + TadrR + 12T + TadrR + 7T + TadrW
7: INC @2(R0) TadrR + 8T + TadrR + 12T + TadrR + 7T + TadrR + 7T + TadrW
Теперь двухадресные команды:
Код:
00: ADD R0, R1 TadrR +8T
10: ADD (R0), R1 TadrR +10T +TadrR +8T
01: ADD R0, (R1) TadrR +10T +(TadrR+8T) +8T
20: ADD (R0)+, R1 TadrR +10T +TadrR +8T
02: ADD R0, (R1)+ TadrR +10T +(TadrR+8T) +10T
30: ADD @(R0)+, R1 TadrR +10T +TadrR +7T +TadrR +8T
03: ADD R0, @(R1)+ TadrR +9T +TadrR +7T +(TadrR+8T) +7T
40: ADD -(R0), R1 TadrR +12T +TadrR +8T
04: ADD R0, -(R1) TadrR +10T +(TadrR+8T) +10T
50: ADD @-(R0), R1 TadrR +10T +TadrR +8T +TadrR +8T
05: ADD R0, @-(R1) TadrR +10T +TadrR +7T +(TadrR+8T) +7T
60: ADD 2(R0), R1 TadrR +10T +TadrR +7T +TadrR +8T
06: ADD R0, 2(R1) TadrR +9T +TadrR +7T +(TadrR+8T) +7T
70: ADD @2(R0), R1 TadrR +10T +TadrR +7T +TadrR +7T +TadrR +8T
07: ADD R0, @2(R1) TadrR +10T +TadrR +7T +TadrR +7T +(TadrR+8T) +8T
Код:
11: ADD (R0), (R1) TadrR+6T+TadrR+7T+(TadrR+8T)+7T
22: ADD (R0)+, (R1)+ TadrR+8T+TadrR+7T+(TadrR+8T)+7T
33: ADD @(R0)+, @(R1)+ TadrR+8T+TadrR+6T+TadrR+6T+TadrR+6T+(TadrR+8T)+6T
44: ADD -(R0), -(R1) TadrR+8T+TadrR+7T+(TadrR+8T)+8T
55: ADD @-(R0), @-(R1) TadrR+8T+TadrR+7T+TadrR+6T+TadrR+7T+(TadrR+8T)+6T
66: ADD 2(R0), 2(R1) TadrR+8T+TadrR+6T+TadrR+6T+TadrR+6T+(TadrR+8T)+6T
77: ADD @2(R0), @2(R1) TadrR+10T+TadrR+6T+TadrR+6T+TadrR+6T+TadrR+6T
+TadrR+6T+(TadrR+8T)+8T
Весьма странная информация..
Из информации об одноадресных командах следует, что процессор 1801ВМ1 не использует цикл "чтение-модификация-запись" при выполнении одноадресных команд. Вместо этого для модификации операнда используется его "полновесное" чтение и затем такая же запись. В таблице же двухадресных команд циклы записи вообще отсутствуют, но зато к последнему циклу чтения делается "добавка" +8T, как бы намекающая на то, что это и не чтение вовсе, а "чтение-модификация-запись".
Но уж слишком это противоречит информации из таблицы времени выполнения одноадресных команд.
...
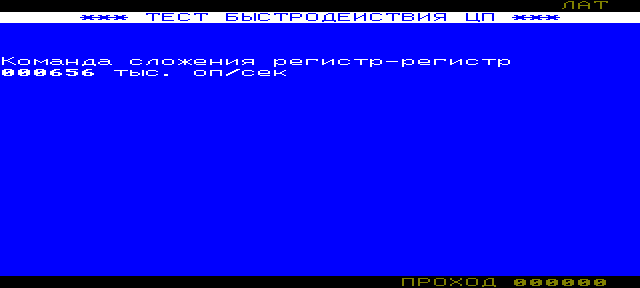
Однако, для практической эмуляции достоверного быстродействия процессора 1801ВМ1 нужны не только точные формулы, но и конкретные значения используемых в вычислениях величин.
С продолжительностью такта процессора всё понятно - при рабочей частоте 1801ВМ1 = 100 кГц - 5 МГц, продолжительность такта составит T = 10 мкс - 0.2 мкс.
[свернуть]





 Ответить с цитированием
Ответить с цитированием
 Размещение рекламы на форуме способствует его дальнейшему развитию
Размещение рекламы на форуме способствует его дальнейшему развитию 

 ). Поэтому выходит, что процессор получает доступ в ОЗУ 1 раз в 5 1/3 такта. В среднем.
). Поэтому выходит, что процессор получает доступ в ОЗУ 1 раз в 5 1/3 такта. В среднем.