толком ничего небыло.




толком ничего небыло.
.
С любовью к вам, Yandex.Direct
Размещение рекламы на форуме способствует его дальнейшему развитию
Мы в своё время игрались с 572ПА1Сообщение от Viktor2312

https://sapr.asvcorp.ru/libr/detail?comp=5438&tcid=95
Восемь. Если будем делать 4 канала, то получится четыре канала по 8 бит.
Надо для начала программную часть прикинуть - что в итоге сможем получить. То есть прикинуть код семплера и по тактам посмотреть что же у нас за звук в итоге получится. Просто пищалку делать неинтересно.
Музей цифровой археологии: http://www.asvcorp.ru/darch/
Занимаюсь разработкой облачного САПР для электронщиков: https://sapr.asvcorp.ru/
Прикинуть можно с довольно большой точностью в эмуляторе. Эмулятор VV поддерживает Covox, например. Про b2m не уверен, но наверняка в нем тоже есть Covox, надо только поискать
Больше игр нет
По-моему, по крайней мере в этой теме, у всех критика конструктивная. Просто многие имеют опыт синтеза звука и сигналов вообще, или подробно изучали вопрос, поэтому представляют себе проблемы которые ему сопутствуют. Интересно ведь когда-нибудь увидеть работающее устройство, а не быть свидетелем того, как куча сил и времени растрачивается на проект, который заведомо не способен выполнить свою задачу.
Больше игр нет
Прикинул код для воспроизведения семплов - то, от чего придётся отталкиваться. Всё выглядит не так страшно, как казалось поначалу.
За счёт некоторого количества фокусов цикл воспроизведения семпла занимает 106 тактов (если с тактами не напутал и если в коде нет ошибок), что при тактовой 2 Мгц даёт частоту дискретизации 18867 Гц, а при тактовой 2,5 Мгц - 23584 Гц.Код:DAC EQU ##### CMD EQU ##### play_sample: lxi h, 0 ; регистр стека будет использоваться dad sp ; не по-назначению, поэтому сохраняем его shsl spsav lhld sample_start ; получаем адрес начала семпла mvi e, 0 ; DE - младшие 16 бит 24-битной "фазы" mov d, l mov c, h ; C - старшие 8 бит 24-битной "фазы" lhld sample_end ; получаем адрес конца семпла mov b, h ; адрес конца семпла должен быть ; выровнен по концу 256-байтного блока! ; т.е. адрес последнего байта семпла ; должен всегда быть XXFFh ; это даёт возможность проверки границы ; одним 8-разрядным сравнением lhld pitch ; значение, определяющее высоту тона ; воспроизведения семпла. к примеру, ; если оно равно 100h, семпл воспроизводится ; побайтно, если равно 200h - семпл ; воспроизводится через один байт ; если равно 80h - семпл воспроизводится ; в два раза медленнее (каждый отсчёт ; выводится дважды) sphl ; SP будет использован для хранения ; этой величины, чтобы всё было ; на регистрах loop: in CMD ; 10 ; это "заглушка" проверки того, ora a ; 4 ; что надо прекращать воспроизводить ноту jm over ; 10 xchg ; 4 ; складываем младшие 16 разрядов "фазы" dad sp ; 10 ; со значением pitch xchg ; 4 ; возвращаем результат в DE mov a, c ; 4 ; прибавляем перенос к старшим 8 разрядам aci 0 ; 7 ; которые хранятся в регистре C mov c, a ; 4 mov l, d ; 4 ; старшие 16 разрядов "фазы" - это адрес mov h, c ; 4 ; очередного отсчёта семпла для вывода в ЦАП cmp b ; 4 ; проверяем, что семпл ещё не закончился jnc over ; 10 ; (про выравнивание семпла написано выше) ; это то самое место, где хорошо экономятся ; такты mov a, m ; 7 ; получаем значение текущего отсчёта out DAC ; 10 ; выводим его в ЦАП jmp loop ; 10 ; повторяем цикл over: lhld spsav sphl ret spsav: dw 0 sample_start: dw 0 sample_end: dw 0 pitch: dw 0 end
Кстати не помню XRA A - чистит бит переноса или нет. Если не чистит,
то можно выиграть три такта на сложении переноса:
Учитывая, что у перкуссиям питч не нужен - всякие хэты можно выдавать и на более высокой частоте.Код:xra a ; 4 ; прибавляем перенос к старшим 8 разрядам adc c ; 4 ; которые хранятся в регистре C mov c, a ; 4
Музей цифровой археологии: http://www.asvcorp.ru/darch/
Занимаюсь разработкой облачного САПР для электронщиков: https://sapr.asvcorp.ru/
Чистит.
Больше игр нет
Тогда, если в "нормальном" состоянии порт CMD будет возвращать ноль,
то это можно использовать для оптимизации на целых семь тактов - предварительно чистить аккумулятор не надо будет.
Музей цифровой археологии: http://www.asvcorp.ru/darch/
Занимаюсь разработкой облачного САПР для электронщиков: https://sapr.asvcorp.ru/
Не то, чтобы нормально, но достаточно, чтобы имело смысл этим заниматься. Звук, конечно, будет глуховат. 2.5 МГц звук сделали бы ощутимо звонче.
Количество каналов в данном случае можно условно рассматривать как количество одновременно звучащих инструментов. Четыре канала - это в каком-то роде необходимый минимум. "Типовая" раскладка: один канал - аккорды (семплы, в которых сразу записано звучание аккордов), второй - сольный, третий - бас, четвёртый - ударные.
Если был бы процессор помощнее, то все эти каналы формировались одним процессором и программно бы смешивались перед выдачей в ЦАП. В нашем же случае более слабый процессор ещё поискать надо - поэтому один процессор кое как может справиться со звучанием только одного инструмента, а смешивать звуки разных каналов придётся "аппаратно". Как это будет выглядеть - зависит от того, что мы хотим получить (индивидуальная громкость на каждый канал, баланс стерео)
Такой способ подключения как минимум обеспечит облегчённую совмещаемость разрабатываемой железки с другими компьютерами.
Сколько разрядов потребуется - станет видно в процессе работы.
У ВМ80 всего может быть 256 портов (для чего требуется 8 адресных линий. На схеме это A0 - A7).
У ВВ55 4 порта, поэтому две младшие адресные линии уходят прямо на него (A0, A1).
Остальные линии идут на дешифратор адреса.
Чтобы произошла выборка ВВ55 линии A4 - A7 обязательно должны иметь нулевое значение.
В зависимости от установленных перемычек будет требоваться разное значение линий A2 и A3. Если они пропускаются через инверторы D14,D15 - то ВВ55 будет активироваться только когда сигналы A2 и A3 равны нулю. В этом случае порты ВВ55 расположены по адресу 00h, 01h, 02h и 03h.
Если A2 и A3 подаются напрямую на D2, то то ВВ55 будет активироваться только когда сигналы A2 и A3 равны единице. В этом случае порты ВВ55 расположены по адресу 0ch, 0dh, 0eh и 0fh.
Как перемычки установлены на схеме - порты расположены по адресам 04h, 05h, 06h и 07h. (подпись на схеме по поводу адреса похоже содержит ошибку).
По поводу памяти - напрашивается объём порядка 512 кб, в идеале доступной сразу всем четырём процессорам. Т.е. смотреть надо в сторону РУ7. Процессоры не должны тормозить друг друга и регенерация памяти не должна тормозить процессор - отличная головоломка на мой взгляд.
Музей цифровой археологии: http://www.asvcorp.ru/darch/
Занимаюсь разработкой облачного САПР для электронщиков: https://sapr.asvcorp.ru/
По-моему система с четырьмя ВМ80 обречена, нельзя такие задачи решать в лоб: прирост пользы линейный, а рост сложности экспоненциальный.
Выборка семплов из памяти и выдача их на ЦАП ничем принципиально не отличается от схемы обновления экрана в любом 8-битном компьютере. Например, вот Вектор: в нем 4 банка памяти, из них одновременно выбираются байты для 4-х экранных плоскостей. Это те же 4 канала звука. Разница в том, что для видео адреса считаются один за другим, а для звука надо выбирать их согласно значению аккумулятора фазы, или по таблице.
Больше игр нет
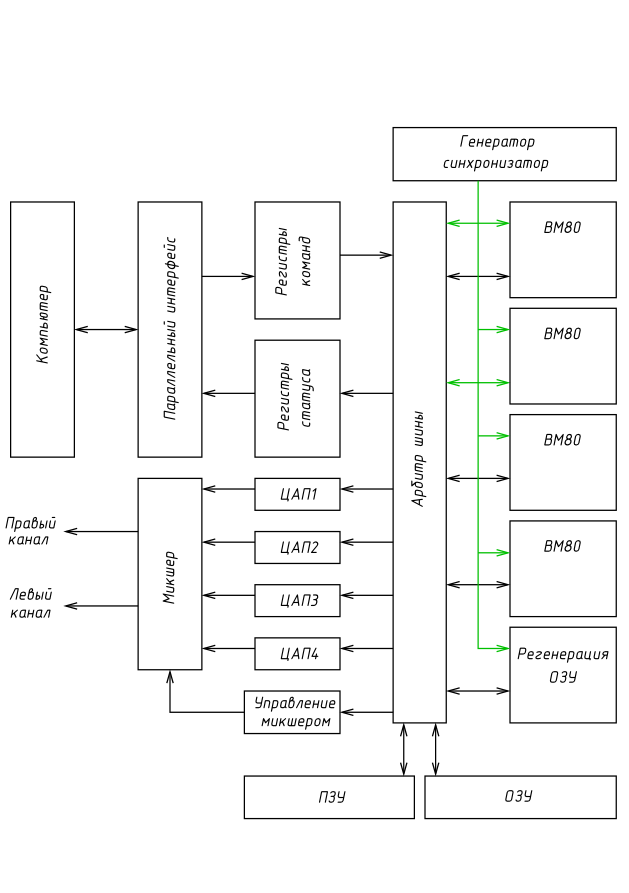
Я пока ни в одном из вариантов не уверен, поэтому надо немного покопать. Для этого я прикинул примерную структурную схему "синтезатора" на ВМ80:
Скрытый текст
[свернуть]
Самое сложное - это генератор и арбитр шины. В случае тактовой процессоров 2 МГц, частота общей шины (с учётом регенерации) получится 10 МГц. В этом месте я в первую очередь начинаю сомневаться в способностях отечественных микросхем ОЗУ и ПЗУ (поэтому-то я и не настаиваю на 2,5 МГц).
Общее ОЗУ хочется хочется сделать, чтобы любой инструмент можно было направить в любой канал, а общее ПЗУ - ну просто зачем четыре экземпляра одного и того же. Да и вообще количество проводов при таком подходе меньше.
Есть также сомнения в том, что получится "развести" на двухсторонней печатной плате... хотя можно поиграться с "трёхмерным" монтажом.
И для такой схемы скорее всего ничего из набора системной логики серии 580 пристроить не получится. Слишком всё "нестандартно".
Музей цифровой археологии: http://www.asvcorp.ru/darch/
Занимаюсь разработкой облачного САПР для электронщиков: https://sapr.asvcorp.ru/
Эту тему просматривают: 1 (пользователей: 0 , гостей: 1)
 Ваши права
Ваши права

 Ответить с цитированием
Ответить с цитированием