

оффтоп
сорри. пьян.




оффтоп
сорри. пьян.
С любовью к вам, Yandex.Direct
Размещение рекламы на форуме способствует его дальнейшему развитию
тут наверно надо смотреть времянки между RES и RES_TCLK кто из них раньше (позже) относительно клока.
Это не важно, т.к. триггер синхронный, и гонка сигналов на него не влияет.Сообщение от AlexG

Еще одна интересная особенность Z80, которая выяснилась при моделировании. Вернее, она видна и по схеме, но не приходило в голову об этом подумать.
Во время сброса процессора, сбрасывается не только счетчик PC, но еще и IR.
Это происходит из-за того, что во время ресета принудительно выбраны PC и IR одновременно. Поэтому при любой записи в PC (в такте T2) или IR (в такте T4), запись идет в оба этих регистра. А так как при сбросе обнуляется регистр инкремента PCR, то каждый цикл записи идет запись 0 в PC и IR, пока не сняли ресет.
Дошел до модели АЛУ, и тут наткнулся на подозрение, что такая конструкция переводится в схему не так, как казалось бы должно:
Код:always @ (negedge clk) // RS-триггер выбора фазы работы АЛУ begin if (start_alu) sel_alu_low = 1; else if (req_alu_high) sel_alu_low = 0; endНо второй триггер почему-то защелкивает результат на 1 такт CLK раньше чем должен.Код:always @ (negedge clk) // Регистр фиксации младшего полубайта результата begin // if (sel_alu_low) // alu_low <= alu_out[7:4]; // end //
Совершенно непонятно, как это может быть.
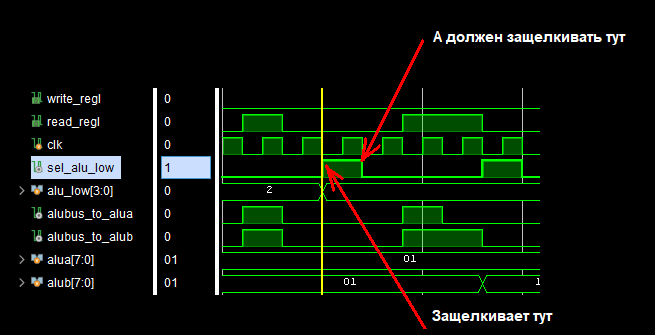
Все, отбой, разобрался.
Это из-за использования неблокирующего присваивания в первом триггере. Странно, что на графике выход триггера выглядит абсолютно правильно, а симулируется неправильно.
Одна из самых нестандартных команд для Z80. Для работы сделаны множество патчей в тех или иных блоках Z80.
Описание на примере команды ADD/ADC HL,DE:
Цикл M1:
T1-T3 - выборка кода команды и завершение предыдущей ALU-операции
T4 - ALUA = L
* Загрузка в регистр PCR текущей выбранной регистровой пары HL (побочка от какой команды?)
Цикл M4:
T1 - ALUB = E
* Инкремент PCR
T2 - сложение младших полубайтов
* Запись PCR в выбранный по умолчанию регистр WZ (фактически в WZ записывается HL + 1)
(побочка от функционала записи декрементированного PC для блочных команд, чтоибы вернуться к началу блочной команды)
T3 - сложение старших полубайтов и запись результата в L
влияние на флаги P/V, Z, S (только для ADC/SBC)
влияние на флаг C
T4 - ALUA = H
флаг C записать во флаг H
Цикл M5:
Т1 - ALUB = D
T2 - сложение младших полубайтов
T3 - сложение старших полубайтов и запись результата в H
Цикл М1:
Т1 - нет стандартного ALU-цикла
T2 - влияние на флаги P/V, Z, S (только для ADC/SBC)
влияние на флаг C
Т3 - нет стандартной записи результата
T4 - сохранение флагов в регистре F
Замечание: флаг N устанавливается для любой стандартной АЛУ-операции
флаг H устанавливается для любой АЛУ-операции
Последний раз редактировалось Titus; 17.11.2024 в 21:51.
Reobne(17.11.2024)
Не смотря на не очень высокий интерес массовой публики к подробным (а уже не подробные, лаконичные) разборам особенностей выполнения команд, все же буду выкладывать интересное)
А именно егодня начал распутываться загадочный клубок с побочной записью/чтением регистра WZ (в некоторых документах его называют MEMPTR).
Обновил чуть выше уже опубликованный сценарий работы команд ADD/ADC/SBC HL,dd, с добавлением комментариев, где, как и почему происходит влияние на регистр WZ.
- - - Добавлено - - -
Фактически, после окончания цикла M1, в котором блок PCR был занят инкрементом PC, а затем IR, блок брошен на произвол судьбы, как пропеллер сорвавшийся с вентилятора) И как только ему попадается какое-то число, он его инкрементирует или декрементирует и обратно выплевывает на шину PCRBUS. В большинстве случаев от этого ничего плохого не происходит, если вдруг какой-то участок схемы, где применялось неполное декодирование условий, вдруг взял и сработал не тогда, когда надо. В нашем случае он сработал два раз, первый раз в такте M1.T4 (тут еще не знаю, побочка от какого функционала), а второй раз в такте M4.T2. Вот тут совершенно четко понятно из-за чего. В этом такте (а так же M4.T4) блочные команды откатывают PC на два шага назад, чтобы вернуться к начальному адресу блочной команды. Но как оказалось, цикл M4 использует для вычислений и команда ADD, функционал которой реализован массовыми патчами разных участков схемы. Работе команды ADD это не помешало, так как запись младшего байта результата происходит в M4.T3, т.е. посередине между M4.T2 и M4.T4. Видимо, авторы проверили, все норм работает, а то, что там попутно куда-то полетели данные в WZ, ну и фиг с ними)
Последний раз редактировалось Titus; 17.11.2024 в 21:54.
Да уж, тема заглохла)
Можно закрывать лавочку за отсутствием интересующихся)
или за отсутствием у них времени на достаточное погружение в тему
ведь чтоб задать правильный вопрос, надо знать б0льшую часть ответа
да еще отрывочно излагаешь, надо бы оформить в статью нормальную
Прихожу без разрешения, сею смерть и разрушение...
Эту тему просматривают: 1 (пользователей: 0 , гостей: 1)
 Ваши права
Ваши права

 Ответить с цитированием
Ответить с цитированием
