
Сообщение от
Vslav

Отладочный nclk остался со времен отладки микроавтомата, тогда его фаза имела смысл, но сейчас его уже можно и вообще удалить.
Сейчас как раз идёт отладка CPP-модели ( методом потактового сравнения содержимого переменных ), поэтому правильная фаза nclk играет важную роль.
- - - Добавлено - - -
Прояснилась причина, по которой CPP-модель не снимала SYNC при снятии RPLY между eval_p() и eval_n().
Сигнал oe_clr_fc использовался в eval_all_n() раньше, чем устанавливался в assign_all(), а поскольку этот сигнал активен только полтакта, то к следующему вызову eval_all_n() сигнал уже снова был сброшен и поэтому SYNC оставался установленным "вечно".
Вообще говоря - используемый в CPP-модели подход методически ложен:
Код:
void eval_n()
{
eval_all_n(); // выполняем все always для переднего фронта
assign_all(pMPI); // вычисляем все assignы
}
Методически корректный подход выглядит так:
Код:
void eval_n()
{
assign_all(pMPI); // вычисляем все assignы
eval_all_n(); // выполняем все always для переднего фронта
assign_all(pMPI); // вычисляем все assignы
}
А практически правильный подход может быть таким:
Код:
void eval_n()
{
assign_in(pMPI); // вычисляем все входные зависимости
eval_all_n(); // выполняем все always для переднего фронта
assign_out(pMPI); // вычисляем все выходные зависимости
}
- - - Добавлено - - -
В ходе тестирования модели QSync выяснился интересный момент.
При осуществлении записи сначала выставляются на шину прошлые данные записи и только затем - новые.
Например, при выполнении на модели процессора 1801ВМ1 следующего кода:
Код:
.ASect
. = 0
MOV R0, (PC)+
NOP
MOV R1, (PC)+
NOP
MOV R2, (PC)+
NOP
MOV R3, (PC)+
NOP
MOV R4, (PC)+
NOP
MOV R5, (PC)+
NOP
MOV SP, (PC)+
NOP
HALT
Процессор пишет в память начальное содержимое регистров:
Код:
gpr[0] = 0133000;
gpr[1] = 0100514;
gpr[2] = 0100410;
gpr[3] = 0040000;
gpr[4] = 0100057;
gpr[5] = 0060000;
gpr[6] = 0000011;
И при выполнении команды MOV R1, (PC)+ - осциллограмма выглядит так:
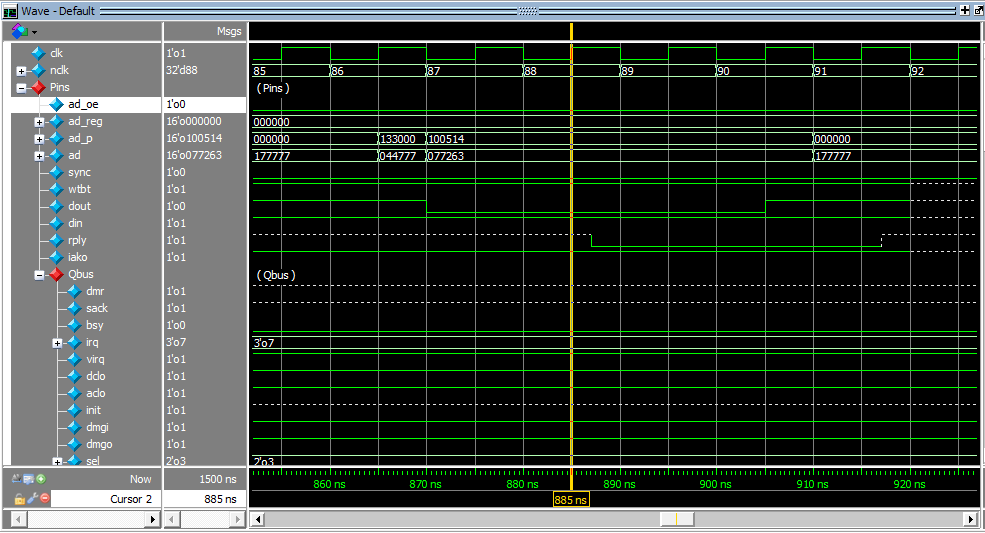
Лог при этом выглядит так:
Код:
# [000085]-1- ad_ena: 0 ; pin_ad_out: 000000 ; dout_out: 0 ; qrd: 133000
#
# [000085]-0- ad_ena: 0 ; pin_ad_out: 000000 ; dout_out: 0 ; qrd: 133000
#
# [000086]-1- ad_ena: 0 ; pin_ad_out: 000000 ; dout_out: 0 ; qrd: 133000
#
# [000086]-0- ad_ena: 1 ; pin_ad_out: 133000 ; dout_out: 1 ; qrd: 133000
#
# [000087]-1- ad_ena: 1 ; pin_ad_out: 100514 ; dout_out: 1 ; qrd: 100514
#
# [000087]-0- ad_ena: 1 ; pin_ad_out: 100514 ; dout_out: 1 ; qrd: 100514
#
# [000088]-1- ad_ena: 1 ; pin_ad_out: 100514 ; dout_out: 1 ; qrd: 100514
#
# [000088]-0- ad_ena: 1 ; pin_ad_out: 100514 ; dout_out: 1 ; qrd: 100514
Интересно, как выглядит аналогичная осциллограмма при выполнении записи реальным 1801ВМ1.





 Ответить с цитированием
Ответить с цитированием

 Размещение рекламы на форуме способствует его дальнейшему развитию
Размещение рекламы на форуме способствует его дальнейшему развитию 

