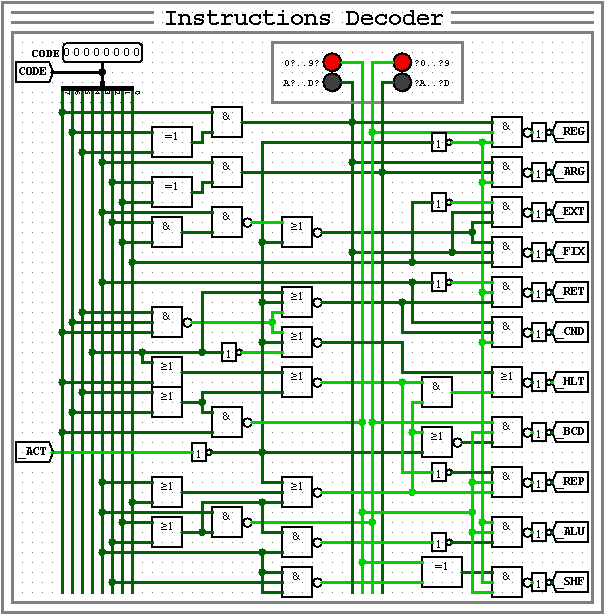
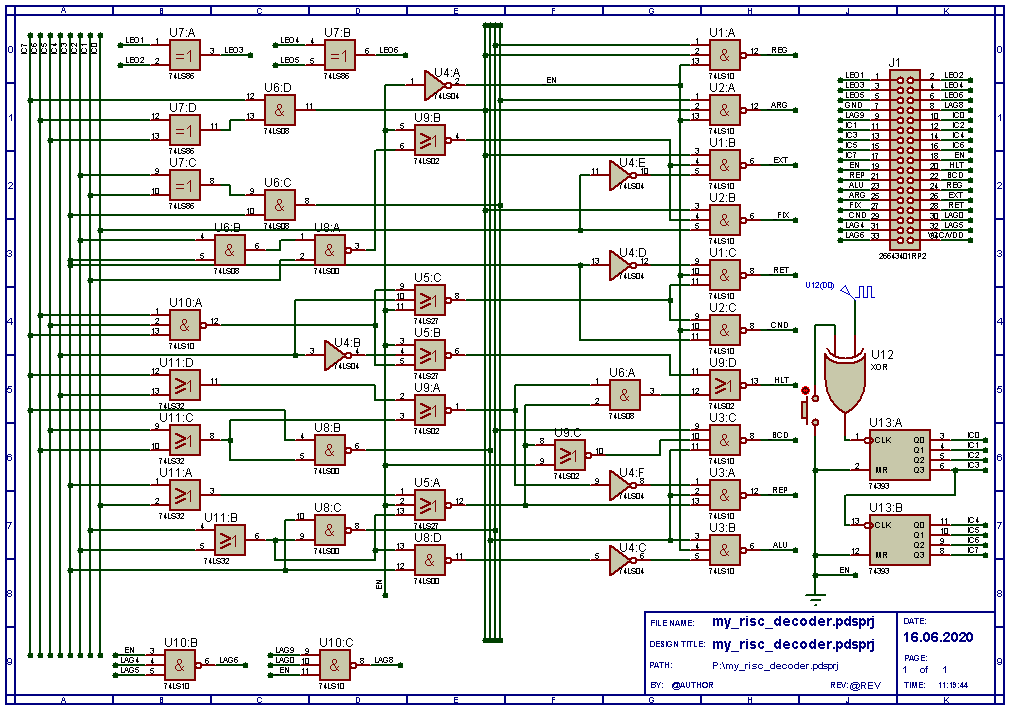
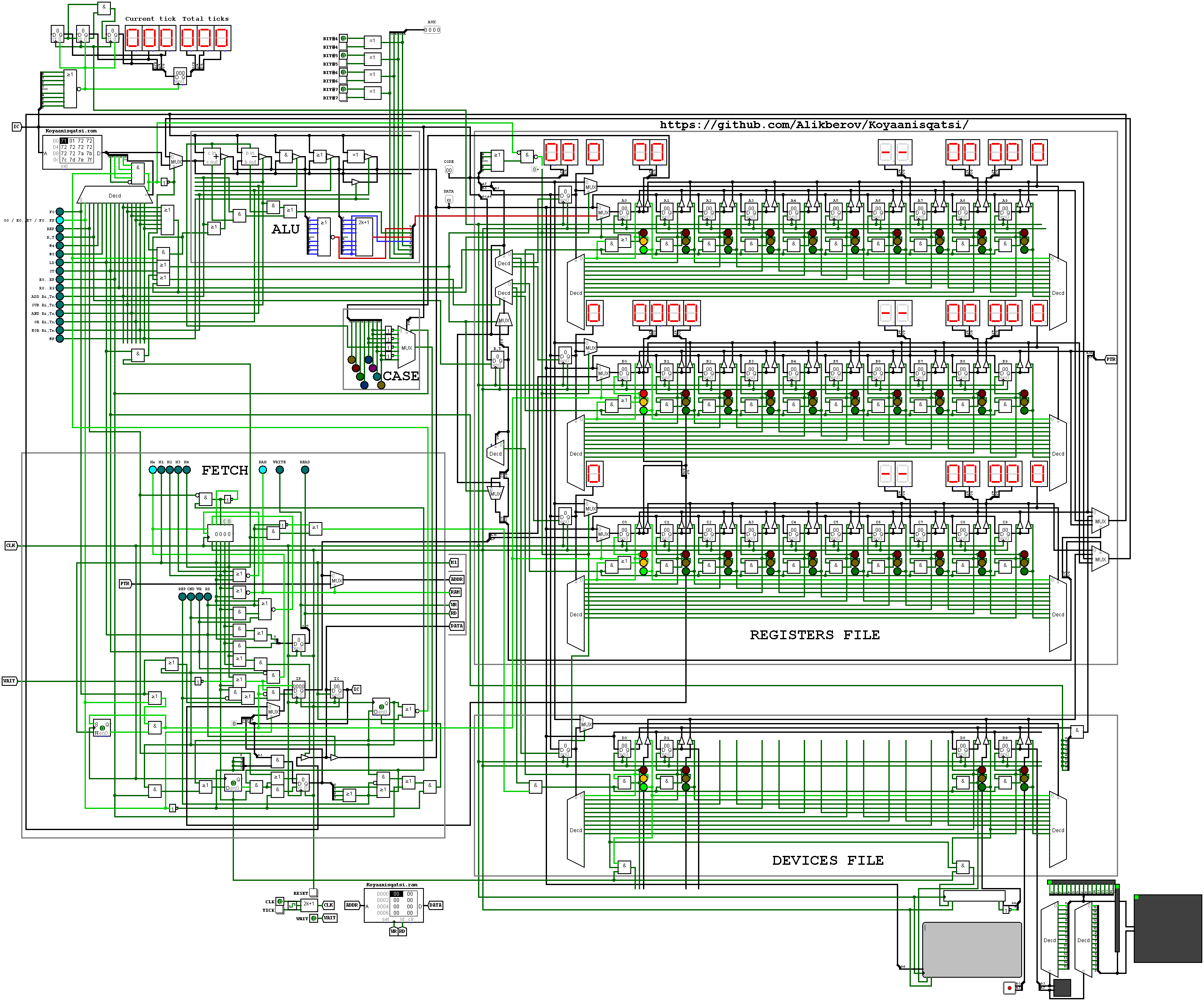
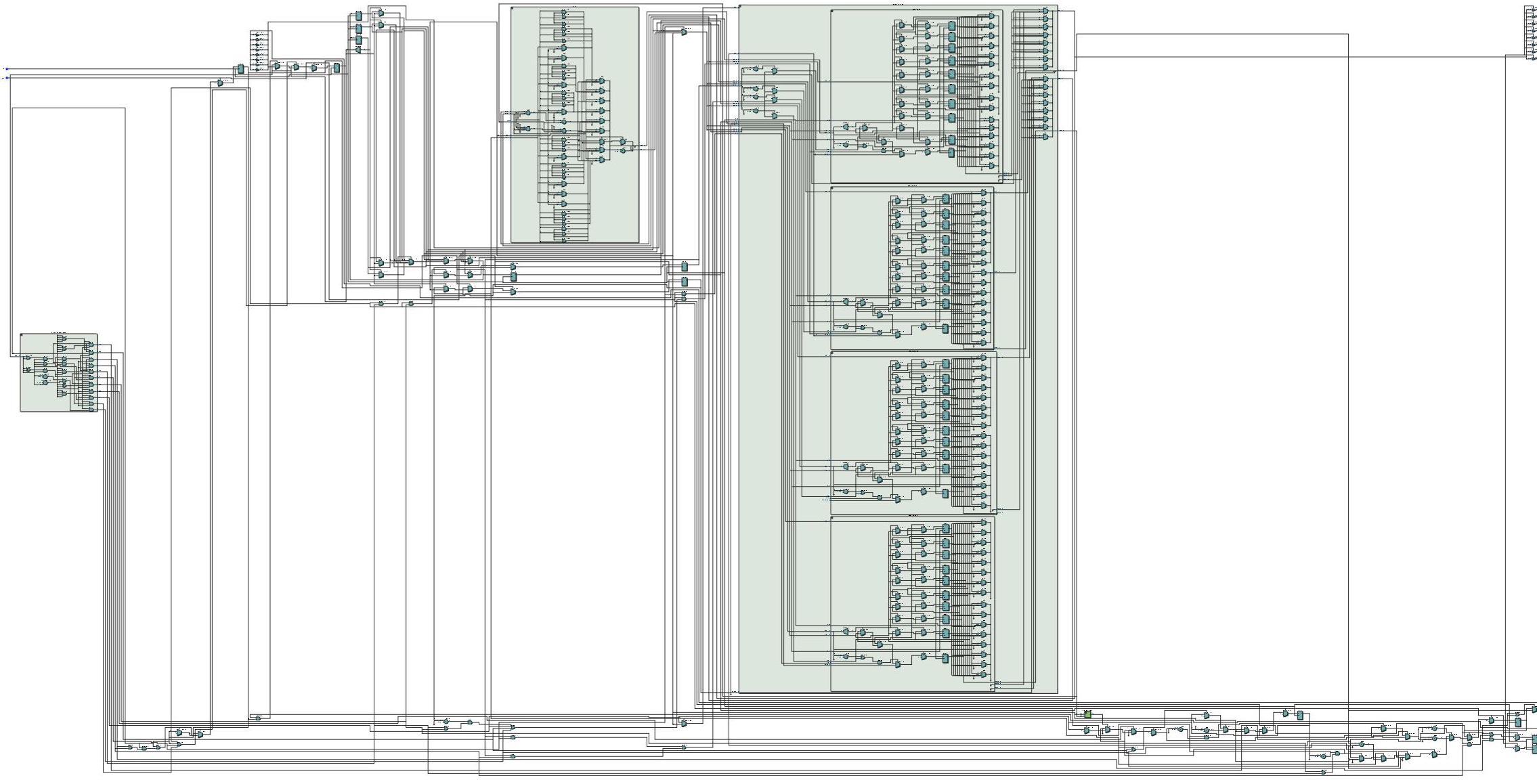
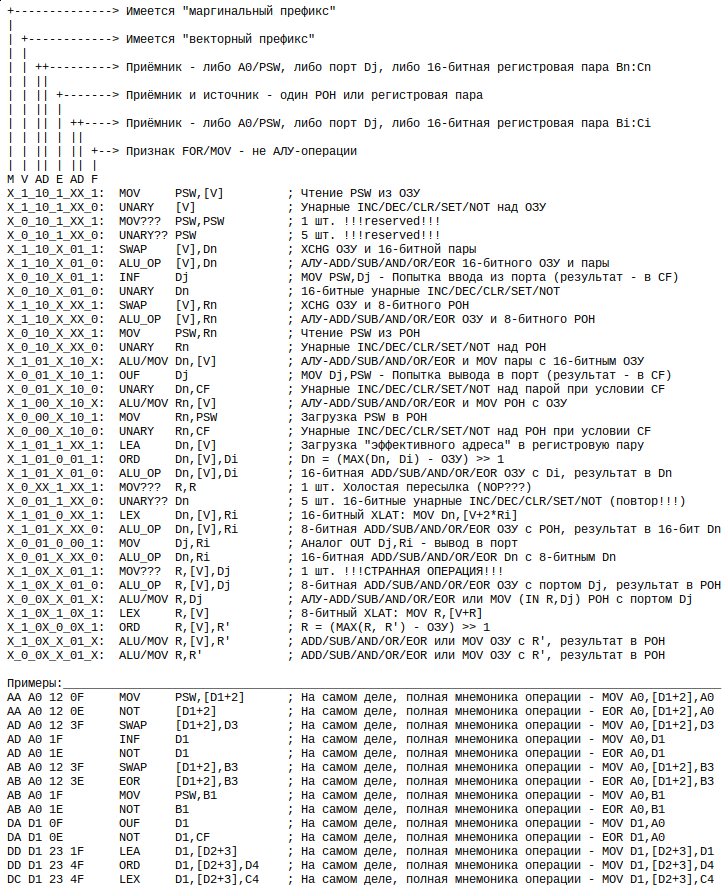
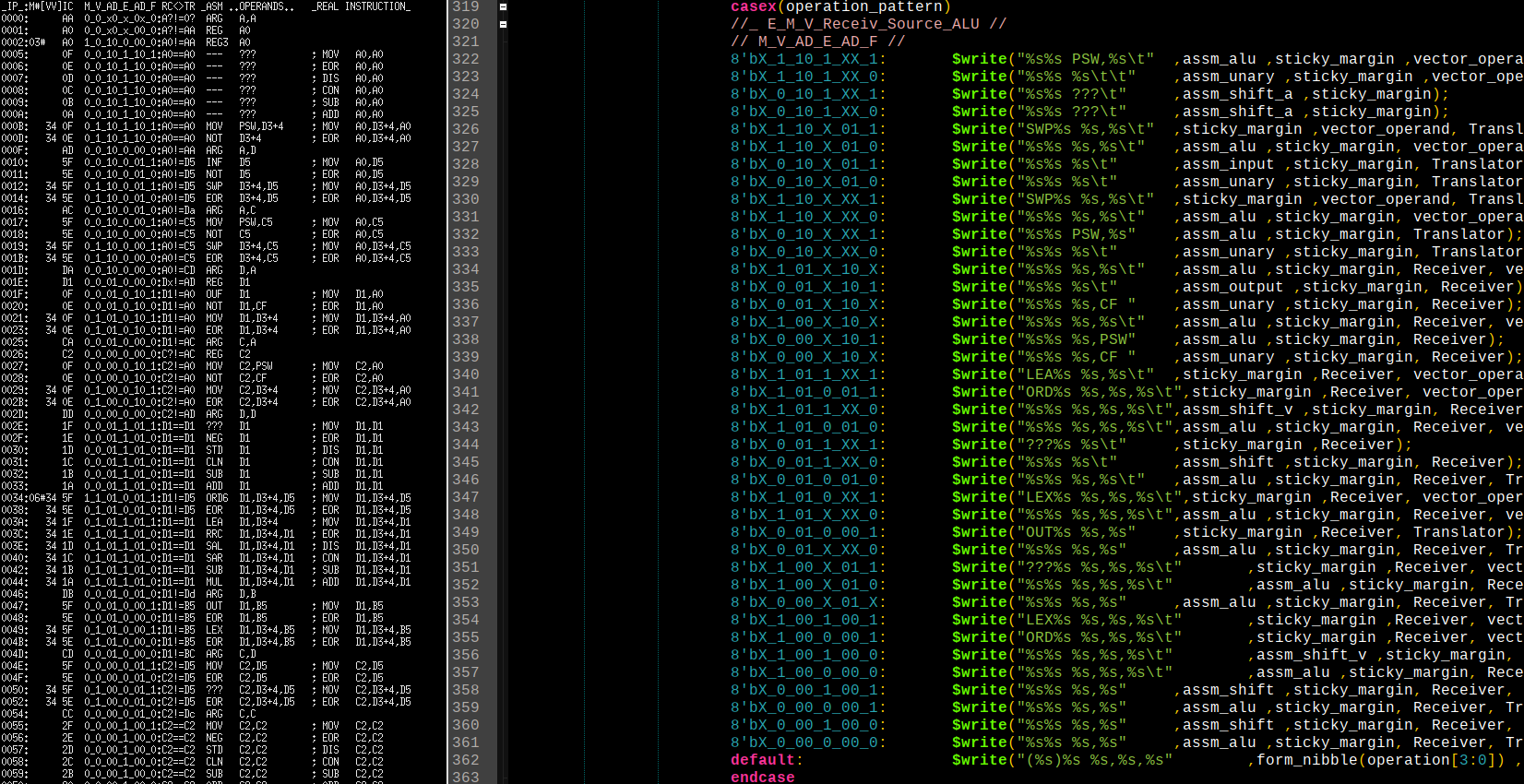
Код:
+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 0. | HLT | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | | D0+1 | D0+2 | D0+3 | D0+4 | D0+5 | D0+6 | D0+7 | D0+8 | D0+9 | R,T0 | R,T0 | R,T0 | R,T0 | R,T0 | R,T0 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 1. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D1+0 | D1+1 | D1+2 | D1+3 | D1+4 | D1+5 | D1+6 | D1+7 | D1+8 | D1+9 | R,T1 | R,T1 | R,T1 | R,T1 | R,T1 | R,T1 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 2. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D2+0 | D2+1 | D2+2 | D2+3 | D2+4 | D2+5 | D2+6 | D2+7 | D2+8 | D2+9 | R,T2 | R,T2 | R,T2 | R,T2 | R,T2 | R,T2 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 3. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D3+0 | D3+1 | D3+2 | D3+3 | D3+4 | D3+5 | D3+6 | D3+7 | D3+8 | D3+9 | R,T3 | R,T3 | R,T3 | R,T3 | R,T3 | R,T3 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 4. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D4+0 | D4+1 | D4+2 | D4+3 | D4+4 | D4+5 | D4+6 | D4+7 | D4+8 | D4+9 | R,T4 | R,T4 | R,T4 | R,T4 | R,T4 | R,T4 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 5. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D5+0 | D5+1 | D5+2 | D5+3 | D5+4 | D5+5 | D5+6 | D5+7 | D5+8 | D5+9 | R,T5 | R,T5 | R,T5 | R,T5 | R,T5 | R,T5 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 6. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D6+0 | D6+1 | D6+2 | D6+3 | D6+4 | D6+5 | D6+6 | D6+7 | D6+8 | D6+9 | R,T6 | R,T6 | R,T6 | R,T6 | R,T6 | R,T6 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 7. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D7+0 | D7+1 | D7+2 | D7+3 | D7+4 | D7+5 | D7+6 | D7+7 | D7+8 | D7+9 | R,T7 | R,T7 | R,T7 | R,T7 | R,T7 | R,T7 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 8. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D8+0 | D8+1 | D8+2 | D8+3 | D8+4 | D8+5 | D8+6 | D8+7 | D8+8 | D8+9 | R,T8 | R,T8 | R,T8 | R,T8 | R,T8 | R,T8 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| 9. | | | | | | | | | | | ADD | SUB | AND | OR | EOR | MOV |
| | D9+0 | D9+1 | D9+2 | D9+3 | D9+4 | D9+5 | D9+6 | D9+7 | D9+8 | D9+9 | R,T9 | R,T9 | R,T9 | R,T9 | R,T9 | R,T9 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| A. | REG | REG | REG | REG | REG | REG | REG | REG | REG | REG | ARG | ARG | ARG | ARG | CLR | NOT |
| | A0 | A1 | A2 | A3 | A4 | A5 | A6 | A7 | A8 | A9 | A,A | A,B | A,C | A,D | AF | AF |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| B. | REG | REG | REG | REG | REG | REG | REG | REG | REG | REG | ARG | ARG | ARG | ARG | CLR | NOT |
| | B0 | B1 | B2 | B3 | B4 | B5 | B6 | B7 | B8 | B9 | B,A | B,B | B,C | B,D | BF | BF |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| C. | REG | REG | REG | REG | REG | REG | REG | REG | REG | REG | ARG | ARG | ARG | ARG | CLR | NOT |
| | C0 | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C,A | C,B | C,C | C,D | CF | CF |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| D. | REG | REG | REG | REG | REG | REG | REG | REG | REG | REG | ARG | ARG | ARG | ARG | CLR | NOT |
| | D0 | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D,A | D,B | C,D | D,D | DF | DF |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| E. | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT |
| | E000 | E100 | E200 | E300 | E400 | E500 | E600 | E700 | E800 | E900 | EA00 | EB00 | EC00 | ED00 | EE00 | EF00 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
| F. | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT | INT |
| | F000 | F100 | F200 | F300 | F400 | F500 | F600 | F700 | F800 | F900 | FA00 | FB00 | FC00 | FD00 | FE00 | FF00 |
+----+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+------+
Где:




 Ответить с цитированием
Ответить с цитированием
 Размещение рекламы на форуме способствует его дальнейшему развитию
Размещение рекламы на форуме способствует его дальнейшему развитию